Mixtext 半监督分类
深度学习的成功一半要归功于模型和计算力,另一半则要归功于数据。 在深度学习的很多领域,监督学习已经取得了很好的成果。当然,
深度学习的成功一半要归功于模型和计算力,另一半则要归功于数据。
在深度学习的很多领域,监督学习已经取得了很好的成果。当然,前提是需要有大量且高质量的标注数据集,通常没有标注的数据集是很多且容易获得的,在深度学习初始阶段,为了解决这个问题,很多公司雇佣廉价劳动力来做数据标注,费时费力还不讨好,当手上有部分标注好的数据集大量未标注数据的时候,如何彻底利用这些数据来建立一个泛化性能能够比肩拥有大量标注数据集的监督学习模型是一个值得深入研究的问题。
背景
在NLP分类任务中同样存在标注数据少的问题,现有的半监督学习:(1)利用VAEs(variational auto encoders )变分自编码重构句子,通过学习重构句子的隐藏变量预测句子的标签(2)通过self-training使模型对无标签的数据输出预测的置信度再加入到训练集去训练模型(3)使用添加扰动(对抗训练)或者数据增强的形式进行训练(4)使用无标签数据训练再用有标签数据微调。上述提及到的方法没有同时使用有标签和无标签数据,在训练过程中可能会过拟合有标签的数据,造成模型泛化性能的降低。Mixtext要做的就是在训练过程中同时利用有标签数据和无标签数据来生成新样本,以增强模型的泛化性能。
亮点
(1)隐空间向量插值
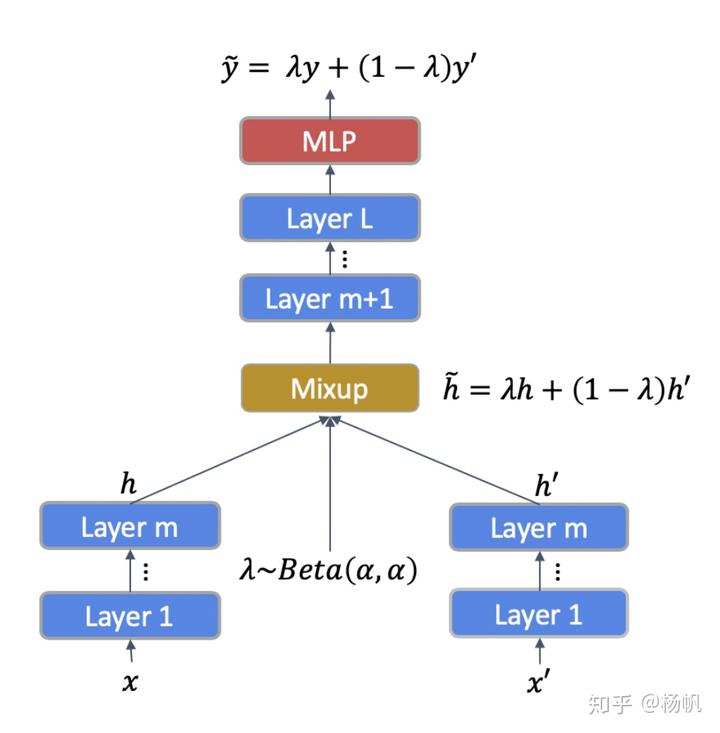
对于两个有标签的样本,在隐空间内进行线性插值获得新的样本,新样本的标签也采用原样本标签的线性插值:

NLP采用了embedding的思想把句子映射到高维空间,在高维空间内插值是合理的,最近 (Jawa-har et al., 2019) 研究表明Bert的不同层有不同的作用,这些层抓住了信息表达的不同形式,从语法层次到语义层次。例如第9层,语义任务表现最出色,第3层预测句子长度最出色。在插值的时候需要考虑 


其中 
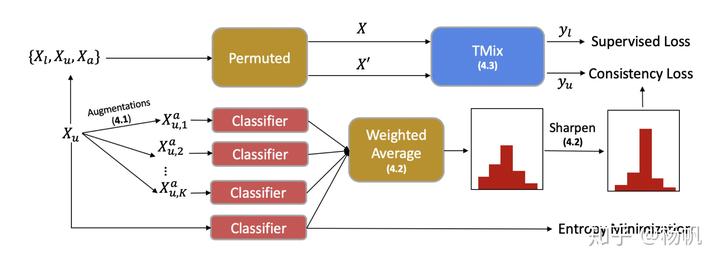
上图为Mixtext的结构示意图,输入





将数据输入模型就能获得模型对其标签分布的预测,再对无标签数据及其增强数据的标签概率做加权平均作为其预测标签。其中 


再对标签锐化,使得其更像真实标签:

T取为0.5 。
这样所有的样本就有了标签,在训练的时候,Mixtext随机从 
(2)损失函数设计
样本的损失函数包括两大类:
(1)样本都来自有标签数据集 
(2)样本都来 

(3)标签猜测最小熵,认为只有猜测的标签熵最小才是准确的猜测,通过损失函数来控制猜测行为。

最终的损失函数表达为:

实验结果
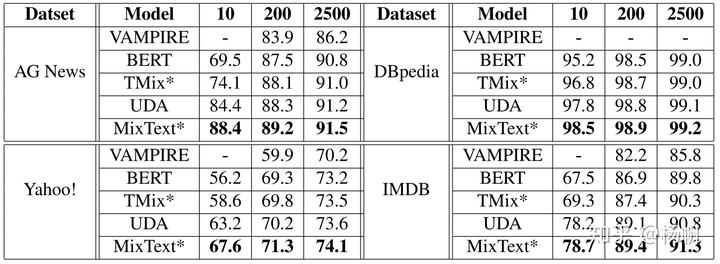
作者在四个不同的数据上做了测试,在样本比较少的时候有明显的提升,在样本量比较大是基本上就没有效果了。
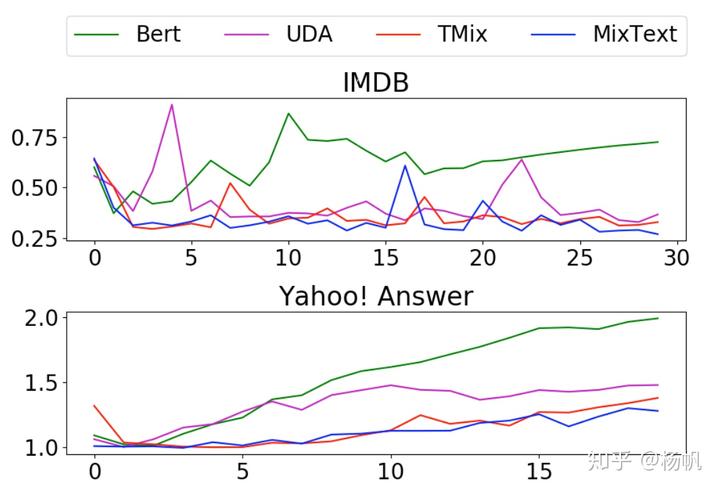
另外对比了一下不同的学习模型的表现,说明了mixtext的多训练几个epoch也不会严重过拟合。
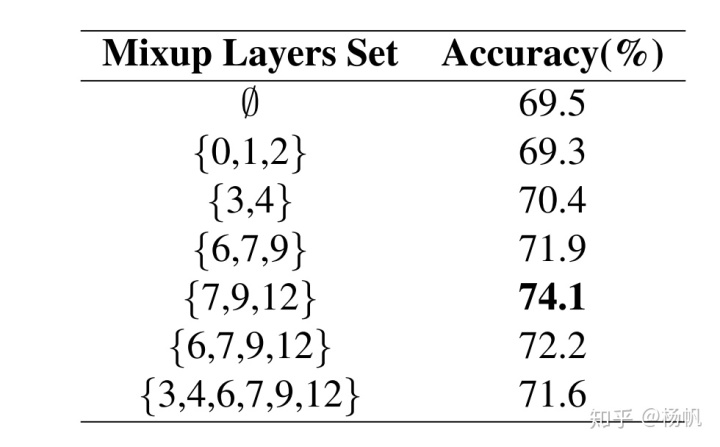
最后研究了一下选取哪些层对结果提升最大,发现对于bert-base(12层)选取7,9,12的表现最好。
个人实验和思考
显然mixtext是一个很有趣的研究,隐空间插值这个很容易想到,但是能做出这么多花样,作者还是下了不少功夫的。我在看到这篇论文以后也是很兴奋的跑到中文数据集上去做测试,结果并没有我想的那么美好。
(1)我在测试时,没有对无标签数据集数据增强,因为google翻译的api实在是太拉垮了。后来查阅了相关文献发现,上面提到的一致性损失对半监督学习十分重要,对无标签数据,希望微小扰动下数据输出基本没有变化,在mixtext中这种微小扰动表现在回译法引起的输入扰动和无标签数据的插值增强的扰动,因此数据增强是体现一致性损失的重要环节。
(2)测试了 

(3)测试了选取不同bert的层,发现确实是{7,9, 12}层的表现好于低层。
可能的改进方向
(1)采用小的 


(2)尝试不同的NLP数据增强,包括回译法,同义词替换,语句翻转等。
(3) 
代码详解
下面为代码运行环境
%%capturen! wget https://raw.githubusercontent.com/PyTorchLightning/pytorch-lightning/master/tests/collect_env_details.pyn! python collect_env_details.pyn##=>ouput :n* CUDA:nt- GPU:ntt- Tesla P100-PCIE-16GBnt- available: Truent- version: 10.1n* Packages:nt- numpy: 1.18.5nt- pyTorch_debug: Truent- pyTorch_version: 1.7.0+cu101nt- pytorch-lightning: 1.1.1rc0nt- tqdm: 4.41.1n* System:nt- OS: Linuxnt- architecture:ntt- 64bitntt- nt- processor: x86_64nt- python: 3.6.9nt- version: #1 SMP Thu Jul 23 08:00:38 PDT 2020
这部分参考了部分代码[1][2][3][4],并在pytorch Ligting中复现。
首先自定义适应于NLP半监督分类的dataset:
class Mydataset(Dataset):n def __init__(self,tokenizer,dataframe,max_seq_len,has_labeled=False,train_aug=False):n super().__init__()n self.tokenizer=tokenizern self.max_seq_len=max_seq_lenn self.has_labeled=has_labeledn self.train_aug=train_augn ## predal datan self.dataframe=self.fliter_data(dataframe)n self.text=self.dataframe["text"]n self.trans_dist = {}n if self.has_labeled:n self.labels=self.dataframe["num_label"]n def __len__(self):n return len(self.text) n n def augment(self, text):n TranslatorF= GoogleTranslator(source='auto', target='en')n TranslatorI= GoogleTranslator(source='auto', target='chinese (simplified)')n if text not in self.trans_dist:n text1 = TranslatorF.translate(text=text)n text2 = TranslatorI.translate(text=text1)n self.trans_dist[text] = text2n return self.trans_dist[text], textn def get_tokenized(self, text):n tokens = self.tokenizer.tokenize(text)n if len(tokens) > self.max_seq_len:n tokens = tokens[:self.max_seq_len]n encode_result = self.tokenizer.convert_tokens_to_ids(tokens)n padding = [0] * (self.max_seq_len - len(encode_result))n encode_result += paddingn return encode_resultn def text_filter(self,sentence: str) -> str:n """n 过滤掉非汉字和标点符号和非数字n :param sentence:n :return:n """n line = sentence.replace('n', '。')n # 过滤掉非汉字和标点符号和非数字n linelist = [word for word in line ifn word >= u'u4e00' and word <= u'u9fa5' or word in [',', '。', '?', '!',n ':'] or word.isdigit()]n return ''.join(linelist)n def fliter_data(self,data):n data['content']=data['content'].astype(str)n data["text"]=data["content"].apply(lambda x:self.text_filter(x))n return data n n def __getitem__(self,idx):n text = self.text[idx]n encode_text = self.get_tokenized(text)n if self.has_labeled:n if self.train_aug:n aug_text = self.augment(text)n encode_aug_text =self.get_tokenized(aug_text)n return {"ids":torch.tensor(encode_text),n "aug_ids":torch.tensor(encode_aug_text),n "lables":self.labels[idx],n "aug_labels":self.labels[idx]n }n else:n return {"ids":torch.tensor(encode_text),n "lables":self.labels[idx]n }n else:n if self.train_aug:n aug_text=self.augment(text)n encode_aug_text = self.get_tokenized(aug_text)n return {"ids":torch.tensor(encode_text),n "aug_ids":torch.tensor(encode_aug_text)n }n else:n return {"ids":torch.tensor(encode_text)n }
这里用has_labeled来区分数据是否有标签,需要重写Dataset的__getitem__方法,返回的变量偏多杂乱,因此采用字典返回,输入的数据为dataset,应该有content和num_label列,把部分的预处理(fliter_data)加载到了dataset中,想改写的也可以按照这个思路把数据预处理部分加载到dataset中。数据增强部分采用:
!pip install -U deep_translator
我测试时,google会检测翻译次数,很快就屏蔽了我的IP,因此没有测试数据增强。
由于训练的时候需要同时传入有标签和无标签的DataLoader,因此采用cat_dataloaders将两个数据集集合为一个使用:
class cat_dataloaders():n """Class to concatenate multiple dataloaders"""nn def __init__(self, dataloaders):n self.dataloaders = dataloadersn len(self.dataloaders)nn def __iter__(self):n self.loader_iter = []n for data_loader in self.dataloaders:n self.loader_iter.append(iter(data_loader))n return selfnn def __next__(self):n out = []n for data_iter in self.loader_iter:n out.append(next(data_iter)) # may raise StopIterationn return tuple(out)nn##使用方法示例:n tokenizer = BertTokenizer.from_pretrained(args.model_name_or_path)n train_labeled_set = Mydataset(tokenizer,train_labeled,args.max_seq_len,has_labeled=True,train_aug=args.train_aug)n train_unlabeled_set = Mydataset(tokenizer,train_ul,args.max_seq_len,has_labeled=False,train_aug=args.train_aug)nn train_labeled=Data.DataLoader(n dataset=train_labeled_set , batch_size=4, shuffle=True)n train_unlabeled=Data.DataLoader(n dataset=train_unlabeled_set , batch_size=12, shuffle=True)n train_dataset=cat_dataloaders([train_labeled,train_unlabeled])
可以对写好的dataset做如下的测试,这样就能知晓是否完成了我们的需求:
next(iter(train_dataset))n##output n({'ids': tensor([[1333, 4868, 4685, ..., 712, 6235, 4955],n [4507, 7471, 2399, ..., 1469, 2300, 7770],n [4507, 1952, 3172, ..., 1139, 671, 702],n [ 857, 2600, 674, ..., 2791, 1912, 1765]]),n 'lables': tensor([7, 8, 7, 8])},n {'ids': tensor([[1277, 1779, 7216, ..., 2769, 1744, 4080],n [3209, 1921, 2218, ..., 4638, 1366, 1384],n [ 686, 4518, 2961, ..., 4802, 924, 6612],n ...,n [ 868, 711, 2900, ..., 1350, 3198, 2213],n [3189, 1184, 6808, ..., 2110, 3136, 2110],
下面开始构建模型:
在bert模型的基础上重新改写模型,尤其是Encoder部分:
class BertEncoder4Mix(nn.Module):n """n reference :n https://github.com/huggingface/transformers/blob/c19d04623eacfbc2c452397a5eda0fde42db3fc5/n src/transformers/models/bert/modeling_bert.py#L458n """n def __init__(self, config):n super().__init__()n self.config = confign self.layer = nn.ModuleList([BertLayer(config) for _ in range(config.num_hidden_layers)])n ## option for output n self.output_attentions = config.output_attentionsn self.output_hidden_states = config.output_hidden_statesn def forward(self,hidden_states,hidden_states2=None,lbeta=None,mixlayer=1000,n attention_mask=None,attention_mask2=None,head_mask=None):n all_hidden_states = () n all_self_attentions = () nn for i, layer_module in enumerate(self.layer):n ## ouput embedings as the first element of all_hidden_state n ## add the last layer_model hidden_states n if self.output_hidden_states:n all_hidden_states = all_hidden_states + (hidden_states,)n # (1) i<mix_layer ,compute tow hidden_state parallel n if i<= mixlayer:n layer_outputs = layer_module(hidden_states, attention_mask, head_mask[i])n hidden_states = layer_outputs[0]n if hidden_states2 is not None:n layer_outputs2 = layer_module(hidden_states2, attention_mask2, head_mask[i])n hidden_states2 = layer_outputs2[0]n n if i == mixlayer:n if hidden_states2 is not None:n hidden_states=lbeta * hidden_states + (1.0 - lbeta) * hidden_states2n # attention_mask=lbeta * attention_mask + (1.0 - lbeta) * attention_mask2n n if i > mixlayer:n layer_outputs =layer_module(hidden_states, attention_mask, head_mask[i])n hidden_states = layer_outputs[0] n ## add each layers attentions n if self.output_attentions:n all_attentions = all_attentions + (layer_outputs[1],)nn ## add the last layer hidden_states n if self.output_hidden_states:n all_hidden_states = all_hidden_states + (hidden_states,)n n ##choose the lastlayer hidden_states as output n outputs = (hidden_states,)n ## output option n if self.output_hidden_states:n outputs = outputs + (all_hidden_states,)n if self.output_attentions:n outputs = outputs + (all_attentions,)n n # return lats_hidden_state,(all_hidden_states,all_attentions)n return outputs
在混合层及其之前,hidden_state 是需要对两个不同的输入都计算的,在mix_layer层进行混合后,输出的hidden_state进入下一层encoder。
重新写的预训练模型可以参考huggingface的BertPreTrainedModel,只需要替换encoder即可。
class BertModel4Mix(BertPreTrainedModel):n '''n regference :n class BertModel(BertPreTrainedModel):n https://github.com/huggingface/transformers/blob/c19d04623eacfbc2c452397a5eda0fde42db3fc5n /src/transformers/models/bert/modeling_bert.py#L746n '''n def __init__(self, config):n super().__init__(config)n self.config=confign self.embeddings=BertEmbeddings(config)n self.encoder = BertEncoder4Mix(config)n self.pooler = BertPooler(config)n self.init_weights()n def _resize_token_embeddings(self, new_num_tokens):n """n Resizes input token embeddings matrix of the modeln if new_num_tokens != config.vocab_size.n """n old_embeddings = self.embeddings.word_embeddingsn new_embeddings = self._get_resized_embeddings(n old_embeddings, new_num_tokens)n self.embeddings.word_embeddings = new_embeddingsn return self.embeddings.word_embeddingsn def _prune_heads(self, heads_to_prune):n """n Prunes heads of the model. heads_to_prune: dict of {layer_num: list of heads to prune in this layer} See basen class PreTrainedModeln """n for layer, heads in heads_to_prune.items():n self.encoder.layer[layer].attention.prune_heads(heads)nn def forward(self,input_ids,input_ids2=None,lbeta=None,mixlayer=1000,attention_mask=None,attention_mask2=None,n token_type_ids=None,token_type_ids2=None,position_ids=None, head_mask=None):n if attention_mask is None:n attention_mask=torch.ones_like(input_ids)n if attention_mask2 is None and input_ids2 is not None :n attention_mask2=torch.ones_like(input_ids2)n if token_type_ids is None:n token_type_ids=torch.zeros_like(input_ids)n if token_type_ids2 is None and input_ids2 is not None:n token_type_ids2=torch.zeros_like(input_ids2)n n device = input_ids.device n input_shape = input_ids.size() n extended_attention_mask: torch.Tensor = self.get_extended_attention_mask(attention_mask, input_shape, device)n if input_ids2 is not None:n extended_attention_mask2:torch.Tensor =self.get_extended_attention_mask(attention_mask2,input_ids2.size(),device)n ## input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]n n head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)n ## Embeding the input n embedding_output = self.embeddings(n input_ids,position_ids=position_ids, token_type_ids = token_type_ids)n if input_ids2 is not None:n embedding_output2 = self.embeddings(n input_ids2,position_ids=position_ids, token_type_ids = token_type_ids2)n n if input_ids2 is not None:n encoder_outputs = self.encoder(embedding_output, embedding_output2, lbeta, mixlayer,n extended_attention_mask, extended_attention_mask2, head_mask=head_mask)n else:n encoder_outputs = self.encoder(embedding_output,attention_mask=extended_attention_mask, head_mask=head_mask)n sequence_output = encoder_outputs[0]n pooled_output = self.pooler(sequence_output) n outputs = (sequence_output, pooled_output,) + encoder_outputs[1:]n return outputs
最后组装模型一定要继承自pl.LightningModule,另外为了参数管理方便,只需要传入args即可。需要注意一些小点为:
(1)self.current_epoch获取当前epoch, 

(2)新建tensor的时候最好采用device=targets_x.device这样的限制,因为Lightning自动把数据迁移到了给定设备上,而新建变量没有限制会默认在CPU上,会出现变量不在同一设备无法计算。
(3)传入的是混合的DataLoader,因此需要分开(batch_labeled,batch_unlabled=batch)
class Mixtext(pl.LightningModule):n def __init__(self, args):n super().__init__()n self.args=argsn self.save_hyperparameters()n config = BertConfig.from_pretrained(self.args.model_name_or_path)n config.output_hidden_states=Truen self.n_labels=self.args.n_labelsn self.train_aug=self.args.train_aug n self.train_crition=SemiLoss()n self.valid_crition=nn.CrossEntropyLoss()n if self.args.mix_option:n self.bert = BertModel4Mix.from_pretrained(self.args.model_name_or_path,config=config)n else:n self.bert = BertModel.from_pretrained(self.args.model_name_or_path,config=config)n n self.linear=nn.Sequential(nn.Linear(config.hidden_size*3,128),n nn.Tanh(),n nn.Linear(128,self.n_labels))n def forward(self,x,x2=None,lbeta=None,mix_layer=1000):n if x2 is not None:n bert_output,pool_output,hidden_output=self.bert(x,x2,lbeta,mix_layer)n else:n bert_output,pool_output,hidden_output=self.bert(x)n # [batch,hidden_dim]*3=>[batch,3*hidden_state]n last_cat = torch.cat(n (pool_output, hidden_output[-1][:, 0,:], hidden_output[-2][:, 0,:]),n 1,n )n predict = self.linear(last_cat)n return predictn ## use multi dataset in one batch n def training_step(self, batch, batch_idx):n # split multi_dataloader n batch_labeled,batch_unlabled=batch n n if self.train_aug:n inputs_x = batch_labeled["ids"]n inputs_x_aug = batch_labeled["aug_ids"]n targets_x = batch_labeled["lables"]n inputs_u = batch_unlabeled["aug_ids"]n inputs_ori = batch_unlabled["ids"]n else:n inputs_x = batch_labeled["ids"]n targets_x = batch_labeled["lables"]n inputs_ori = batch_unlabled["ids"]n batch_size=inputs_x.size(0)n ##scatter_(dim,index,src_value)n targets_x = torch.zeros(batch_size, self.n_labels,device=targets_x.device).scatter_(1, targets_x.view(-1, 1), 1)n ## make predict on unlabeled data n with torch.no_grad():n outputs_ori = self(inputs_ori)n if self.train_aug:n outputs_u=self(inputs_u)n #[batch,n_labels]n p=0*torch.softmax(ouputs_u,dim=1)+1.0*torch.softmax(outputs_ori,dim=1)n pt=p**(1.0/self.args.T)n target_u=pt/pt.sum(dim=1,keepdim=True)n target_u=target_u.detach()n else:n p=1.0*torch.softmax(outputs_ori,dim=1)n pt=p**(1.0/self.args.T)n target_u=pt/pt.sum(dim=1,keepdim=True)n target_u=target_u.detach()n n #choose lbeta n lbeta = np.random.beta(self.args.alpha, self.args.alpha)n lbeta=max(1.0-lbeta,lbeta)n ##choose mix layern mix_layer = np.random.choice(self.args.mix_layers_set, 1)[0]n mix_layer = mix_layer - 1n n ##make mixed n if self.train_aug:n all_inputs=torch.cat([inputs_x,inputs_x_aug,inputs_u,inputs_ori],dim=0)n all_targets=torch.cat([targets_x,targets_x,target_u,target_u],dim=0)n else:n all_inputs=torch.cat([inputs_x,inputs_ori],dim=0)n all_targets=torch.cat([targets_x,target_u],dim=0)n ## [input_labeled,input_unlabled] &(mix) ## random idx n idx=torch.randperm(all_inputs.size(0))n input_a, input_b = all_inputs, all_inputs[idx]n target_a, target_b =all_targets, all_targets[idx]n n logits=self(input_a,input_b,lbeta,mix_layer)n mix_target=lbeta*target_a + (1.0-lbeta)*target_b n n ## compute loss n if self.train_aug:n labeled_index=inputs_x.size(0)+inputs_x_aug.size(0)n else:n labeled_index=inputs_x.size(0)n Lx, Lu, w, Lu2, w2 = self.train_crition(logits[:labeled_index],mix_target[:labeled_index],n logits[labeled_index:],mix_target[labeled_index:],n self.current_epoch)n loss = Lx + w*Lu + w2*Lu2n n self.log('train_loss', loss)n return lossn n def validation_step(self,batch,batch_idx):n x=batch["ids"]n y=batch["lables"]n y_logits=self(x)n loss=self.valid_crition(y,y_logits)n self.log("val_loss", loss) n n def configure_optimizers(self):n return AdamW(n [n {"params": self.bert.parameters(), "lr": self.args.lrmain},n {"params": self.linear.parameters(), "lr": self.args.lrlast},n ])
损失函数定义为:
def linear_rampup(current, rampup_length=args.epochs):n if rampup_length == 0:n return 1.0n else:n current = np.clip(current / rampup_length, 0.0, 1.0)n return float(current)nclass SemiLoss(object):n def __call__(self, outputs_x, targets_x, outputs_u, targets_u, epoch):n probs_u = torch.softmax(outputs_u, dim=1)n probs_u = torch.softmax(outputs_u, dim=1)n n ## crossEntropy n Lx = -torch.mean(torch.sum(F.log_softmax(outputs_x, dim=1)*targets_x,dim=1))n n ##一致性损失n Lu = torch.mean((probs_u - targets_u)**2)n n ## 最小熵损失 >=args.magrin n n Lu2 = torch.mean(torch.clamp(torch.sum(-F.softmax(outputs_u,dim=1)n *F.log_softmax(outputs_u, dim=1),dim=1)- args.margin, min=0))n #Lx,Lu,w1,Lu2,w2n return Lx, Lu, args.lambda_u * linear_rampup(epoch), Lu2, args.lambda_u_hinge * linear_rampup(epoch)




