JUC 并发容器
原文作者:热爱可抵漫长岁月原文链接:https://juejin.cn/post/7063655099465203742Java 容器在我们平常项目中使用实在是太频繁了,比
原文作者:热爱可抵漫长岁月
原文链接:https://juejin.cn/post/7063655099465203742
Java 容器在我们平常项目中使用实在是太频繁了,比如 ArrayList、HashMap、HashSet 这三个,但有一点需要我们注意,这三个容器在并发环境下是线程不安全的。
所以我们在并发环境下如果要使用容器的话,java.util.concurrent 包下为我们提供了一些线程安全的容器,并且还能在保证线程安全的条件下性能也不差。如 ConcurrentHashMap、CopyOnWriteArrayList、CopyOnWriteArraySet 等。
1、HahMap 线程不安全
解决方法:n(1)使用 Hashtable 替代 HashMapn(2)Collections.synchronizedMap()n(3)使用 ConcurrentHashMap 代替 HashMap(推荐使用)
数据丢失问题
先看源码:
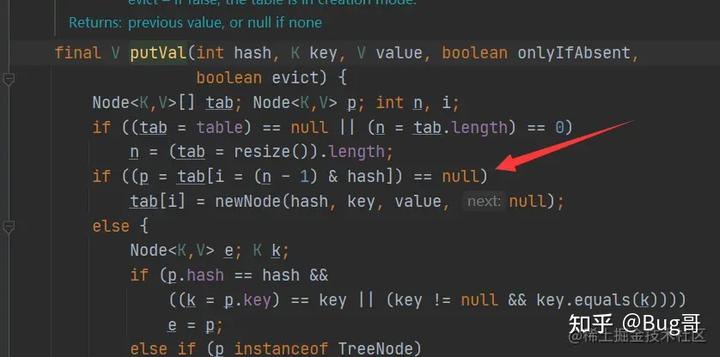
假如两个线程同时进入 if ((p = tab[i = (n - 1) & hash]) == null) 这一行,假设对应的位置为 null。
这也就意味着两个线程可以同时进入 if 包含的代码块(线程上下文切换),恰好两个 put 的位置是一样的(如 key 相等或者哈希冲突,哈希冲突正常情况下应该用拉链法解决)。结果就是后一个线程的数据会覆盖前一个线程的数据。
也就是数据丢失问题。
可见性问题
可见性:当一个线程操作这个容器的时候,该操作需要对另外的线程都可见,也就是其他线程都能感知到本次操作。
HashMap 是无法做到的。
死链问题
在 JDK 1.7 的时候是采用链表头插法的,这种情况下扩容的时候会造成链表死循环。
JDK 1.7 源码如下:
void transfer(Entry[] newTable, boolean rehash) {n int newCapacity = newTable.length;n for (Entry<K,V> e : table) {n while(null != e) {n Entry<K,V> next = e.next;n if (rehash) {n e.hash = null == e.key ? 0 : hash(e.key);n }n int i = indexFor(e.hash, newCapacity);n e.next = newTable[i];n newTable[i] = e;n e = next;n }n }n}
- e 和 next 都是局部变量,用来指向当前节点和下一个节点
- 线程 1(绿色)的临时变量 e 和 next 刚引用了这俩节点,还未来得及移动节点,发生了线程切换,由线程 2(蓝色)完成扩容和迁移
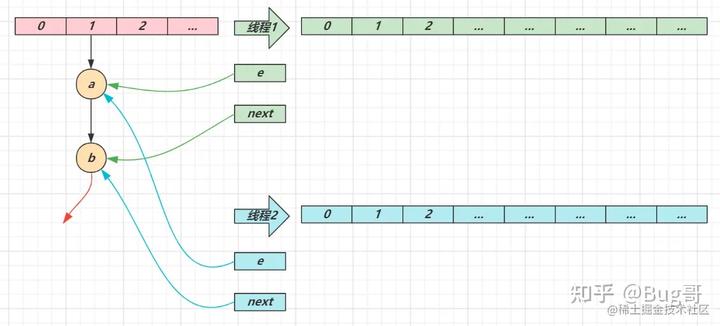
线程 2 扩容完成,由于头插法,链表顺序颠倒。但线程 1 的临时变量 e 和 next 还引用了这俩节点,还要再来一遍迁移
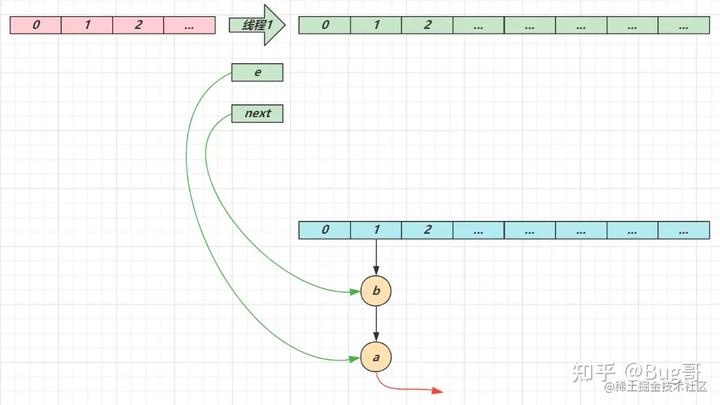
第一次循环
- 循环接着线程切换前运行,注意此时 e 指向的是节点 a,next 指向的是节点 b
- e 头插 a 节点,注意图中画了两份 a 节点,但事实上只有一个(为了不让箭头特别乱画了两份)
- 当循环结束是 e 会指向 next 也就是 b 节点
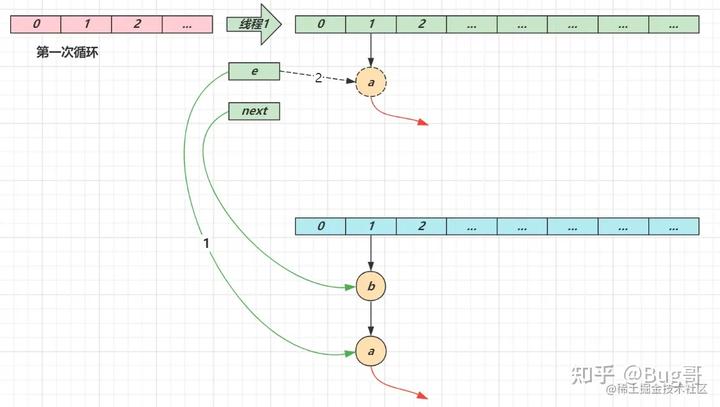
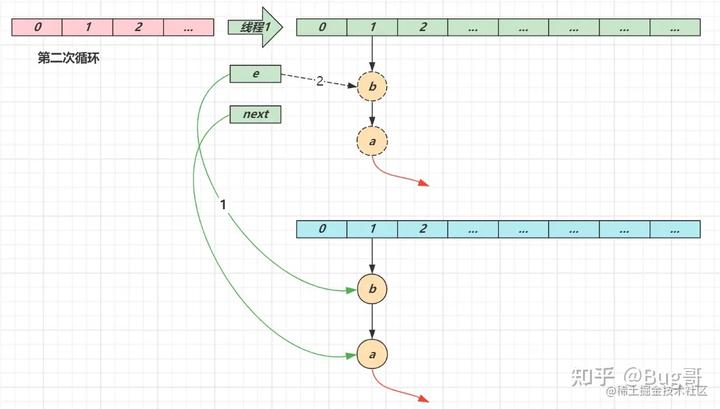
第二次循环
- next 指向了节点 a
- e 头插节点 b
- 当循环结束时,e 指向 next 也就是节点 a
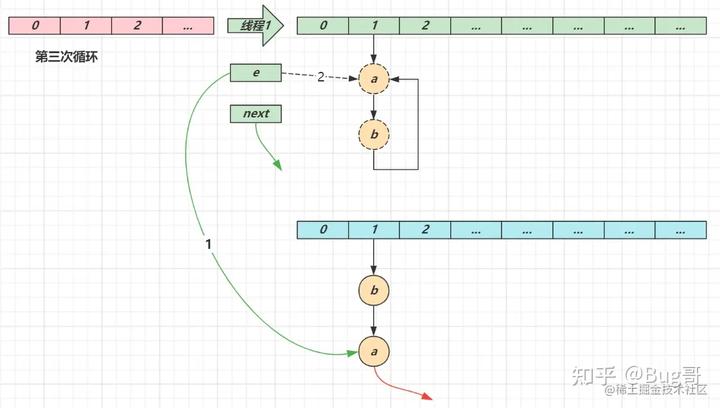
第三次循环
- next 指向了 null
- e 头插节点 a,a 的 next 指向了 b(之前 a.next 一直是 null),b 的 next 指向 a,死链已成
- 当循环结束时,e 指向 next 也就是 null,因此第四次循环时会正常退出
2、ConcurrentHashMap 分析
面试题:ConcurrentHashMap 在 JDK 1.7 和 JDK 1.8 中的结构分别是什么?它们有什么相同点和不同点?
JDK 1.7
整体结构图:
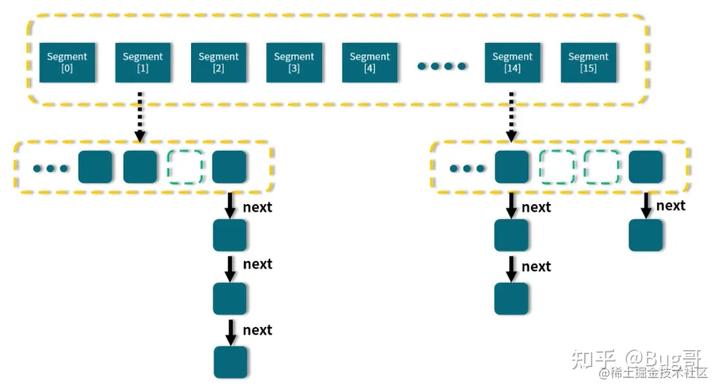
可以看出,在 ConcurrentHashMap 内部进行了 Segment 分段,Segment 继承了 ReentrantLock,可以理解为一把锁,各个 Segment 之间都是相互独立上锁的,互不影响。
相比于 Hashtable 每次操作都需要把整个对象锁住而言,大大提高了并发效率。因为它的锁与锁之间是独立的,而不是整个对象只有一把锁。
每个 Segment 的底层数据结构与 HashMap 类似,仍然是数组和链表组成的拉链法结构。默认有 16 个 Segment,所以最多可以同时支持 16 个线程并发操作(操作分别分布在不同的 Segment 上)。16 这个默认值可以在初始化的时候设置为其他值,但是一旦确认初始化以后,是不可以扩容的。
JDK 1.8
整体结构图:
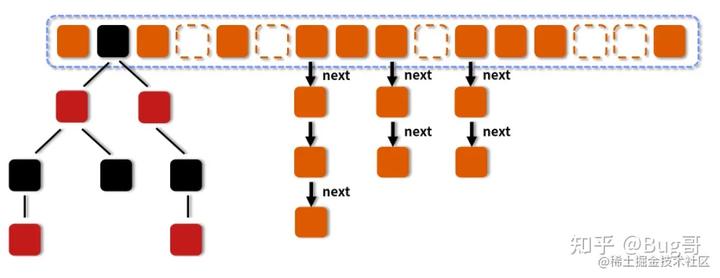
图中的节点有三种类型:
- 第一种是最简单的,空着的位置代表当前还没有元素来填充。
- 第二种就是和 HashMap 非常类似的拉链法结构,在每一个槽中会首先填入第一个节点,但是后续如果计算出相同的 Hash 值,就用链表的形式往后进行延伸。
- 第三种结构就是红黑树结构,这是 JDK 1.7 的 ConcurrentHashMap 中所没有的结构,了解过 HashMap 的话应该知道这个。
当链表长度大于 8,数组长度 >= 64 时,链表会转化为红黑树。
红黑树特点:
红黑树是每个节点都带有颜色属性的二叉查找树,颜色为红色或黑色,红黑树的本质是对二叉查找树 BST 的一种平衡策略,我们可以理解为是一种平衡二叉查找树,查找效率高,会自动平衡,防止极端不平衡从而影响查找效率的情况发生。
查找时间复杂度为:O(logN),因为如果链表在某些极端情况下太长的话,查找时间复杂度为 O(N),这也就是引入红黑树的原因,主要是为了性能。
节点颜色规定:
- 每个节点要么是红色,要么是黑色,但根节点永远是黑色的。
- 红色节点不能连续,也就是说,红色节点的子和父都不能是红色的。
- 从任一节点到其每个叶子节点的路径都包含相同数量的黑色节点。
JDK 1.8 源码分析
Node 节点
(1)ConcurrentHashMap 的 Node 节点源码:
static class Node<K,V> implements Map.Entry<K,V> {n final int hash;n final K key;n volatile V val;n volatile Node<K,V> next;n}
(2)HashMap 的 Node 节点源码:
static class Node<K,V> implements Map.Entry<K,V> {n final int hash;n final K key;n V value;n Node<K,V> next;n}
很明显,在 value 和 next 属性上加了 volatile 关键字。为了保证可见性。
put 方法
源码如下:
// 实际上是调用了 putVal 方法npublic V put(K key, V value) {n return putVal(key, value, false);n}nn// 真正的添加元素逻辑实现nfinal V putVal(K key, V value, boolean onlyIfAbsent) {n if (key == null || value == null) throw new NullPointerException();n // 计算 hash 值,方法源码写在下面了,和 HashMap 有点不一样n int hash = spread(key.hashCode());n int binCount = 0;n for (Node<K,V>[] tab = table;;) {n Node<K,V> f; int n, i, fh;n // 哈希桶为空,进行相应的初始化过程n if (tab == null || (n = tab.length) == 0)n tab = initTable();n // 找到哈希值对应的哈希桶下标n else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {n // 以 CAS 的方式放入新的值,方法源码写在下面了n if (casTabAt(tab, i, null,n new Node<K,V>(hash, key, value, null)))n break; // no lock when adding to empty binn }n // hash 值等于 MOVED,代表在扩容n else if ((fh = f.hash) == MOVED)n tab = helpTransfer(tab, f);n // 对应哈希桶下标有值的情况n else {n V oldVal = null;n // 用 synchronized 锁住当前位置,保证并发安全,synchronized 在 JDK 1.6 后做了优化n synchronized (f) {n if (tabAt(tab, i) == f) {n // 如果是链表n if (fh >= 0) {n binCount = 1;n // 遍历链表n for (Node<K,V> e = f;; ++binCount) {n K ek;n if (e.hash == hash &&n ((ek = e.key) == key ||n (ek != null && key.equals(ek)))) {n oldVal = e.val;n if (!onlyIfAbsent)n e.val = value;n break;n }n Node<K,V> pred = e;n // 遍历了整个链表也没有发现相同的值,说明之前不存在该值,添加到链表尾部n if ((e = e.next) == null) {n pred.next = new Node<K,V>(hash, key,n value, null);n break;n }n }n }n // 如果是红黑树n else if (f instanceof TreeBin) {n Node<K,V> p;n binCount = 2;n // 调用 putTreeVal 方法往红黑树里增加数据n if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,n value)) != null) {n oldVal = p.val;n if (!onlyIfAbsent)n p.val = value;n }n }n }n }n if (binCount != 0) {n // 检查是否满足条件并把链表转换为红黑树的形式,默认的 TREEIFY_THRESHOLD 阈值是 8n if (binCount >= TREEIFY_THRESHOLD)n treeifyBin(tab, i);n // putVal 的返回是添加前的旧值,所以返回 oldValn if (oldVal != null)n return oldVal;n break;n }n }n }n addCount(1L, binCount);n return null;n}nnstatic final int spread(int h) {n return (h ^ (h >>> 16)) & HASH_BITS;n}nnstatic final <K,V> boolean casTabAt(Node<K,V>[] tab, int i,n Node<K,V> c, Node<K,V> v) {n return U.compareAndSwapObject(tab, ((long)i << ASHIFT) + ABASE, c, v);n}
get 方法
public V get(Object key) {n Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;n int h = spread(key.hashCode());n if ((tab = table) != null && (n = tab.length) > 0 &&n (e = tabAt(tab, (n - 1) & h)) != null) {n if ((eh = e.hash) == h) {n if ((ek = e.key) == key || (ek != null && key.equals(ek)))n return e.val;n }n else if (eh < 0)n return (p = e.find(h, key)) != null ? p.val : null;n while ((e = e.next) != null) {n if (e.hash == h &&n ((ek = e.key) == key || (ek != null && key.equals(ek))))n return e.val;n }n }n return null;n}
JDK 1.7 和 JDK 1.8 对比
数据结构
JDK 1.7:Segment 分段锁
JDK 1.8:数组 + 链表 + 红黑树
并发度
JDK 1.7:每个 Segment 独立加锁,最大并发个数就是 Segment 的个数,默认是 16。
JDK 1.8:锁粒度更细,理想情况下 table 数组元素的个数(也就是数组长度)就是其支持并发的最大个数,并发度比之前有提高。
保证并发安全
JDK 1.7:采用 Segment 分段锁来保证安全,而 Segment 是继承自 ReentrantLock。
JDK 1.8:采用 Node + CAS + synchronized 保证线程安全。
遇到 Hash 碰撞
JDK 1.7:在 Hash 冲突时,会使用拉链法,也就是链表的形式。
JDK 1.8:先使用拉链法,当链表长度大于 8,数组长度 >= 64 时,链表会转化为红黑树,来提高查找效率。
查询时间复杂度
JDK 1.7:遍历链表的时间复杂度是 O(N),n 为链表长度。
JDK 1.8:如果变成遍历红黑树,那么时间复杂度降低为 O(logN),n 为树的节点个数。
与 Hashtable 的区别
实现线程安全的方式不同
Hashtable 是使用 synchronized 来保证线程安全的。
ConcurrentHashMap 是使用 CAS + synchronized + volatile 来保证线程安全的。
性能不同
Hashtable 把整个对象给锁了,而 ConcurrentHashMap 只锁单个节点,所以并发性能比 Hashtable 好。
迭代时修改的不同
Hashtable(包括 HashMap)不允许在迭代期间修改内容,否则会抛出 ConcurrentModificationException 异常,其原理是检测 modCount 变量,Hashtable 的 next() 方法源码如下:
public T next() {n if (modCount != expectedModCount)n throw new ConcurrentModificationException();n return nextElement();n}
ConcurrentHashMap 即便在迭代期间修改内容,也不会抛出 ConcurrentModificationException。
3、CopyOnWriteArrayList 分析
从 JDK 1.5 开始,Java 并发包里提供了使用 CopyOnWrite 机制实现的并发容器 CopyOnWriteArrayList 作为主要的并发 List,CopyOnWrite 的并发集合还包括 CopyOnWriteArraySet,其底层正是利用 CopyOnWriteArrayList 实现的。
核心就是读写分离。
适用场景
- 读操作可以尽可能的快,而写即使慢一些也没关系
比如,有些系统级别的信息,往往只需要加载或者修改很少的次数,但是会被系统内所有模块频繁的访问。
- 读多写少
读写规则
- 读写锁的规则
读写锁的思想是:读读共享、其他都互斥(写写互斥、读写互斥、写读互斥)。
- 对读写锁规则的升级
CopyOnWriteArrayList 的思想比读写锁的思想又更进一步。为了将读取的性能发挥到极致,CopyOnWriteArrayList 读取是完全不用加锁的,更厉害的是,写入也不会阻塞读取操作,也就是说你可以在写入的同时进行读取,只有写入和写入之间需要进行同步,也就是不允许多个写入同时发生,但是在写入发生时允许读取同时发生。这样一来,读操作的性能就会大幅度提升。
特点
- CopyOnWrite的含义
CopyOnWrite 的意思是说,当容器需要被修改的时候,不直接修改当前容器,而是先将当前容器进行 Copy,复制出一个新的容器,然后修改新的容器,完成修改之后,再将原容器的引用指向新的容器。这样就完成了整个修改过程。
CopyOnWriteArrayList 利用了不变性原理,因为容器每次修改都是创建新副本,所以对于旧容器来说,其实是不可变的,也是线程安全的,无需进一步的同步操作。所以可以对 CopyOnWrite 容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素,也不会有修改。
核心思想就是读写分离。
- 迭代期间允许修改集合内容
ArrayList 在迭代期间如果修改集合的内容,会抛出 ConcurrentModificationException 异常。根据 modCount 的值是否改变来判断。
CopyOnWriteArrayList 的迭代器一旦被建立之后,如果往之前的 CopyOnWriteArrayList 对象中去新增元素,在迭代器中既不会显示出元素的变更情况,同时也不会报错。
缺点
- 内存占用问题
因为 CopyOnWrite 的写时复制机制,所以在进行写操作的时候,内存里会同时驻扎两个对象的内存,这一点会占用额外的内存空间。
- 在元素较多或者复杂的情况下,复制的开销很大
复制过程不仅会占用双倍内存,还需要消耗 CPU 等资源,会降低整体性能。
- 数据一致性问题
由于 CopyOnWrite 容器的修改是先修改副本,所以这次修改对于其他线程来说,并不是实时能看到的,只有在修改完之后才能体现出来。如果你希望写入的的数据马上能被其他线程看到,CopyOnWrite 容器是不适用的。
源码分析
数据结构
// 非公平锁nfinal transient ReentrantLock lock = new ReentrantLock();n// 底层就是一个数组,加了 volatile 关键字来保证可见性nprivate transient volatile Object[] array;nn// 获取数组nfinal Object[] getArray() {n return array;n}nn// 设置数组nfinal void setArray(Object[] a) {n array = a;n}nn// 空构造方法npublic CopyOnWriteArrayList() {n setArray(new Object[0]);n}
add 方法
public boolean add(E e) {n final ReentrantLock lock = this.lock;n lock.lock();n try {n // 获取原数组n Object[] elements = getArray();n // 获取原数组长度n int len = elements.length;n // 复制一个新数组n Object[] newElements = Arrays.copyOf(elements, len + 1);n // 将新元素添加到新数组n newElements[len] = e;n // 设置新数组为 array 的引用n setArray(newElements);n return true;n } finally {n lock.unlock();n }n}
CopyOnWrite 的思想:写操作是在原来容器的拷贝上进行的,并且在读取数据的时候不会锁住 list。而且可以看到,如果对容器拷贝操作·的过程中有新的读线程进来,那么读到的还是旧的数据,因为在那个时候对象的引用还没有被更改。
get 方法
private E get(Object[] a, int index) {n return (E) a[index];n}nnpublic E get(int index) {n return get(getArray(), index);n}
可以发现,get 操作并没有上锁。
迭代器 COWIterator 类
private COWIterator(Object[] elements, int initialCursor) {n // 迭代器的游标n cursor = initialCursor;n // 数组的快照n snapshot = elements;n}
之后的迭代器所有的操作都基于 snapshot 数组进行的,比如:
public E next() {n if (! hasNext())n throw new NoSuchElementException();n return (E) snapshot[cursor++];n}




