GPT2
Language Models are Unsupervised Multitask LearnersGPT2 - TZ blog语言模型是一个无监督的多任务学习器使用webText数据集训
Language Models are Unsupervised Multitask Learners
GPT2 - TZ blog
语言模型是一个无监督的多任务学习器
使用webText数据集训练15亿参数的GPT2,zero-sho在多个任务上取得了SOTA的结果。并且在WebText数据上仍然欠拟合(underfits)
语言模型的容量对zero shot任务的迁移是很重要的,并且增加容量可以以对数线性方式提高模型性能。模型参数大小是x轴,性能是y轴。
作者认为:单领域数据集上单任务的训练是当前模型泛华能力不足的原因,多任务学习根据元学习角度,每一个(dateset,objective)是从datasets和objects的分布中采样,仍然需要较多的目标训练数据。
预训练和监督微调的方法组合也是一个方法,但是仍然是监督学习,作者展示了语言模型可以在zero-shot下执行下游任务,不需要参数或架构的修改。
Approach
单任务可以用一个条件分布表示 $p(output|input)$ 多任务$p(output|input, task)$,对于不同task的处理之前通过设计特殊的encoder 和decoder,通过模型架构来处理多任务。但是语言也提供了灵活的方式来标识不同的task。
作者通过语言模型zero-shot在多任务的性能的表现,来衡量语言模型是否是一个无监督多任务学习器。
数据
尽可能大和多样化(多领域)
Comon Crawl 存在质量问题。“内容大多难以理解”
从社交媒体Reddit抓取outbound links,有4500万个链接,清理去重后有800万个文档,总40GB的文本。(删除了Wikipedia的文档。因为是通用数据源可能造成训练和测试数据的重叠。)
数据输入
需要有一个词汇表,来包含130000个unicode字符。(Unicode 13.0共有143859个字符),这比BPE通用的32k和64k词表大太多。byte bpe仅仅需要256的vocab大小。16*16
采用BPE,作者发现在BPE 词表中有很多变体,如dog为dog. dog! dog? 这因为bpe使用频率的启发式贪心算法导致suboptimal merges。
所以作者组织BPE合并跨字符类比的字符。并且为空格添加了一个exception
(暂不知操作是什么)
提高压缩效率,添加最少的单词碎片。
这样使模型在任何数据集上都可以进行模型评估。
模型
词表大小 50257
batch size 512, context sieze 1024
实验

训练了四个模型。模型参数大小的差距是log近似 log(parameters)约等于1,每个模型的学习率都是手动调整的以至于在5%webtext保留数据集上获得最好的困惑度。所有模型仍然欠拟合,

Children's Book Test(CBT) 检查LM在不同词类的表现,命名实体,名词,动词介词。将模型完形填空的准确率作为评价指标。
LAMDADA:系统对文本中远程依赖建模的能力,预测句子的最后一个单词。
GPT2的错误预测情况下大多是句子的延续而不是句子结尾的最后一个单词。表明LM没有使用单词必须是结尾的约束条件。添加一个停用词过滤会将准确率从
52.66%提升到63.24%。
Winograd Schema Challenge:衡量系统解决文本歧义的能力来衡量系统执行常识推理的能力。
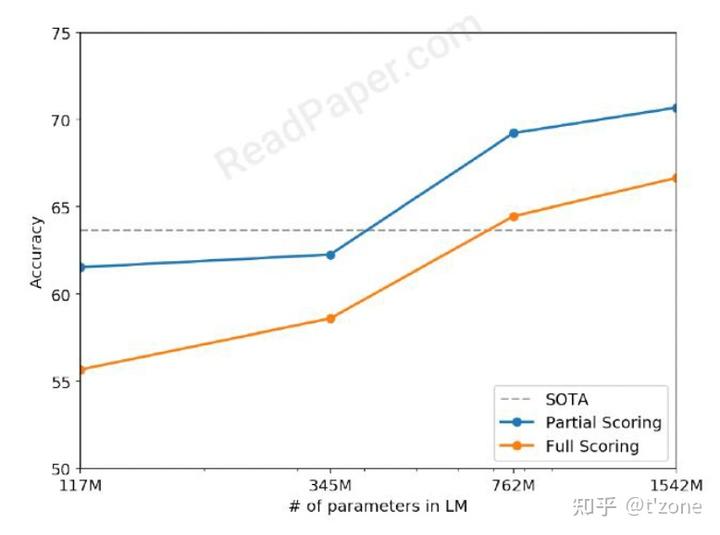
CoQA Conversation Question Answering:
GPT2 在开发集上55 F1(zero shot)。SOTA 是bert进行监督学习 89F1. 从错误预测的数据中作者发现,GPT2经常使用简单的,基于启发式的检索方法。例如用文档中的名字回答Who问题。
CNN and Daily Mail dataset [Summarization]
为了诱导模型摘要的能力,在文档之后添加文本 TL;DR,使用top-k随机抽样,k=2,减少重复并估计更抽象的摘要。
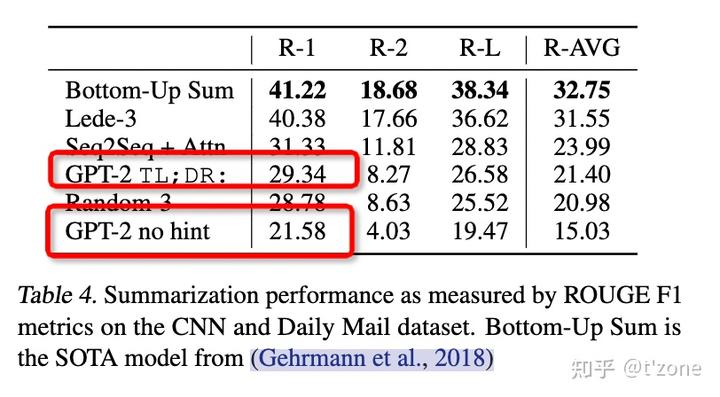
当任务提示移出后,GPT2的指标下降了6.4,这证明可以使用自然语言调用模型针对特定任务的行为。
WMT14-En-Fr
wmt14-en-fr :GPT2 5BLEU,
Wmt14-fr-en: GPT2 11.5 BLEU. 得益于英文的语言模型。 最好的无监督机器翻译方法 BLUE是33.5 。差的还比较多。
Question-answer
SQUAD: GPT2 准确回答了4.1%的准确率。最小的模型准确率低于1%。(Who,What,Where),GPT2在最小信息的1%的数据上有63.1%准确率
泛化与记忆
基于8-gram重叠作为重复句子,判断webtext数据和其他测试数据集的重复率
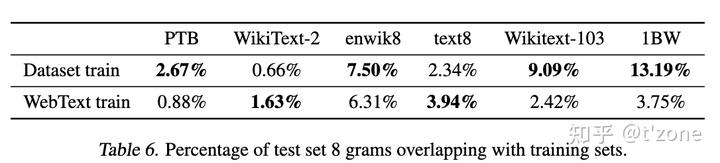
作者建议在新的NLP数据集上创建训练或测试拆分期间,基于n-gram重复的验证是有必要的。
下图可以看出,模型仍然是欠拟合。

相关工作
Jozefowicz et al. (2016) 在10亿word上训练RNN语言模型。
语言模型有趣的功能Karpathy et al. (2015). ,line-width tracking and quote/comment detection
(Ramachandran et al., 2016) 证明了seq2seq模型受益于预训练语言模型作为编码器和解码器的初始化。
(Wolf et al., 2019) (Dinan et al., 2018) LM pre-training 在对话和困难生成任务上进行微调也有很帮助
讨论
虽然作为研究结果具有启发性,但是实际应用,GPT2的零样本性能仍远未可用。
尚不清楚GPT2微调的上限。
并且不清楚GPT2的额外训练数据和容量是否能够克服BERT所展示单向表示的低效率(Devlin et al., 2018).2




